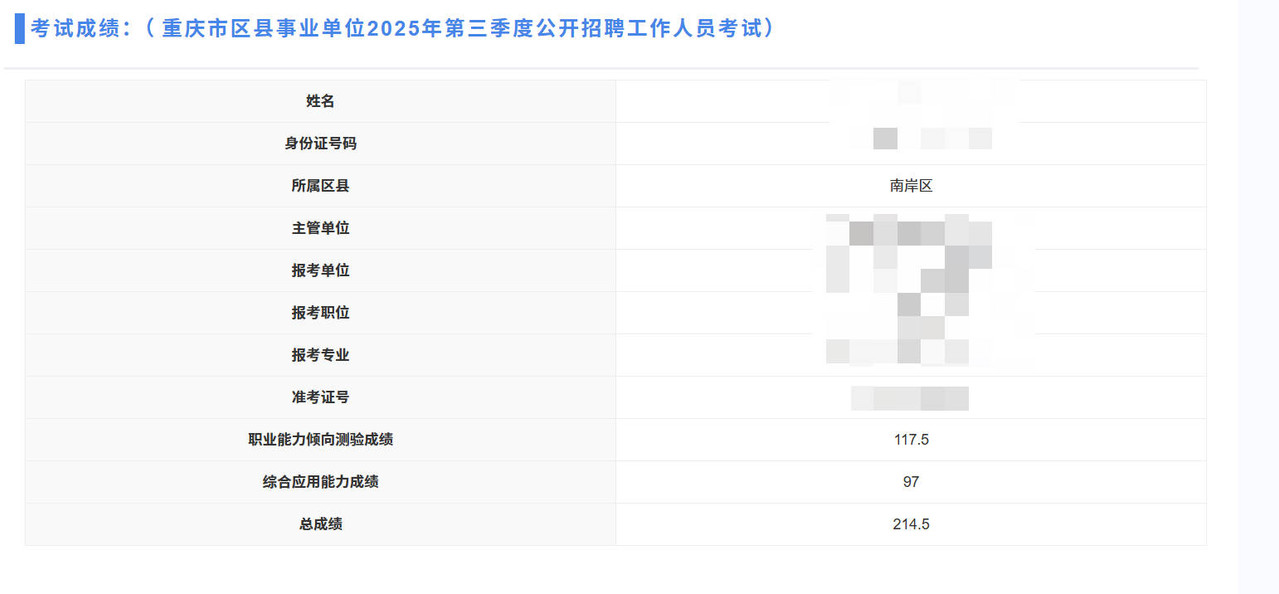
Correlation Analysis
期货品种相关性分析¶
做这个分析的原因在于后续有个实盘量化策略,策略是捕获趋势,但是我们知道,很多品种其实是有相关性的,所以我们这里需要分析一下品种相关性,选取不相关的或者相关度低的品种进行测试。
数据准备以及必要库¶
- 数据这里就不提供了,大家自行想办法,毕竟数据也是资产,可以直接看后面的分析结论
- 必要库安装:
pip install pandas numpy matplotlib seaborn plotly scipy statsmodels
导入必要的库¶
In [15]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体和图表样式
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
sns.set_style("whitegrid")
plt.rcParams['figure.figsize'] = (12, 8)
加载数据并预处理¶
In [16]:
def load_and_preprocess_data(data_dir="file"):
"""
加载所有CSV文件并预处理数据
"""
data_dir = Path(data_dir)
csv_files = list(data_dir.glob("*_daily.csv"))
all_data = {}
for file in csv_files:
try:
# 从文件名提取品种名称
symbol = file.stem.split('_daily')[0]
symbol = symbol.replace('KQ_m_', '').replace('SHFE_', '').replace('DCE_', '')
symbol = symbol.replace('CZCE_', '').replace('CFFEX_', '').replace('INE_', '').replace('GFEX_', '')
# 读取数据
df = pd.read_csv(file)
# 确保有必要的列
if 'datetime' in df.columns and 'close' in df.columns:
# 转换日期格式
df['datetime'] = pd.to_datetime(df['datetime'])
df.set_index('datetime', inplace=True)
# 只保留收盘价
df = df[['close']].rename(columns={'close': symbol})
# 去除缺失值
df = df.dropna()
if len(df) > 0:
all_data[symbol] = df
print(f"✓ 已加载 {symbol}: {len(df)} 个数据点")
else:
print(f"⚠ 跳过 {symbol}: 无有效数据")
else:
print(f"⚠ 跳过 {file.name}: 缺少必要列")
except Exception as e:
print(f"✗ 加载 {file.name} 时出错: {e}")
return all_data
# 加载数据
data_dict = load_and_preprocess_data()
✓ 已加载 IC: 1000 个数据点 ✓ 已加载 IF: 1000 个数据点 ✓ 已加载 IH: 1000 个数据点 ✓ 已加载 TF: 1000 个数据点 ✓ 已加载 TS: 1000 个数据点 ✓ 已加载 T: 1000 个数据点 ✓ 已加载 AP: 1000 个数据点 ✓ 已加载 CF: 1000 个数据点 ✓ 已加载 CJ: 1000 个数据点 ✓ 已加载 CY: 1000 个数据点 ✓ 已加载 FG: 1000 个数据点 ✓ 已加载 MA: 1000 个数据点 ✓ 已加载 OI: 1000 个数据点 ✓ 已加载 PF: 729 个数据点 ✓ 已加载 PK: 650 个数据点 ✓ 已加载 RM: 1000 个数据点 ✓ 已加载 RS: 1000 个数据点 ✓ 已加载 SA: 931 个数据点 ✓ 已加载 SF: 1000 个数据点 ✓ 已加载 SM: 1000 个数据点 ✓ 已加载 SR: 1000 个数据点 ✓ 已加载 TA: 1000 个数据点 ✓ 已加载 UR: 1000 个数据点 ✓ 已加载 ZC: 1000 个数据点 ✓ 已加载 a: 1000 个数据点 ✓ 已加载 b: 1000 个数据点 ✓ 已加载 cs: 1000 个数据点 ✓ 已加载 c: 1000 个数据点 ✓ 已加载 eb: 977 个数据点 ✓ 已加载 eg: 1000 个数据点 ✓ 已加载 i: 1000 个数据点 ✓ 已加载 jm: 1000 个数据点 ✓ 已加载 j: 1000 个数据点 ✓ 已加载 l: 1000 个数据点 ✓ 已加载 m: 1000 个数据点 ✓ 已加载 pg: 857 个数据点 ✓ 已加载 pp: 1000 个数据点 ✓ 已加载 p: 1000 个数据点 ✓ 已加载 rr: 1000 个数据点 ✓ 已加载 v: 1000 个数据点 ✓ 已加载 y: 1000 个数据点 ✓ 已加载 lc: 53 个数据点 ✓ 已加载 si: 191 个数据点 ✓ 已加载 bc: 701 个数据点 ✓ 已加载 lu: 801 个数据点 ✓ 已加载 nr: 1000 个数据点 ✓ 已加载 sc: 1000 个数据点 ✓ 已加载 ag: 1000 个数据点 ✓ 已加载 al: 1000 个数据点 ✓ 已加载 au: 1000 个数据点 ✓ 已加载 bu: 1000 个数据点 ✓ 已加载 cu: 1000 个数据点 ✓ 已加载 fu: 1000 个数据点 ✓ 已加载 hc: 1000 个数据点 ✓ 已加载 ni: 1000 个数据点 ✓ 已加载 pb: 1000 个数据点 ✓ 已加载 rb: 1000 个数据点 ✓ 已加载 ru: 1000 个数据点 ✓ 已加载 sn: 1000 个数据点 ✓ 已加载 sp: 1000 个数据点 ✓ 已加载 ss: 978 个数据点 ✓ 已加载 wr: 1000 个数据点 ✓ 已加载 zn: 1000 个数据点
建统一的时间序列数据框¶
In [3]:
def create_unified_dataframe(data_dict):
"""
创建统一时间索引的数据框
"""
# 合并所有数据
combined_df = pd.concat([df for df in data_dict.values()], axis=1)
# 向前填充缺失值(可选,根据分析需求)
# combined_df = combined_df.ffill().dropna()
# 或者只保留所有品种都有数据的日期
combined_df = combined_df.dropna()
print(f"合并后数据形状: {combined_df.shape}")
print(f"时间范围: {combined_df.index.min()} 至 {combined_df.index.max()}")
return combined_df
# 创建统一数据框
price_df = create_unified_dataframe(data_dict)
price_df.head()
合并后数据形状: (53, 63) 时间范围: 2023-07-21 00:00:00+08:00 至 2023-10-11 00:00:00+08:00
Out[3]:
| IC | IF | IH | TF | TS | T | AP | CF | CJ | CY | ... | hc | ni | pb | rb | ru | sn | sp | ss | wr | zn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| datetime | |||||||||||||||||||||
| 2023-07-21 00:00:00+08:00 | 5925.4 | 3834.0 | 2519.0 | 102.370 | 101.400 | 102.355 | 8590.0 | 17300.0 | 10930.0 | 23850.0 | ... | 3933.0 | 170530.0 | 15925.0 | 3823.0 | 12115.0 | 234090.0 | 5234.0 | 15340.0 | 4126.0 | 20200.0 |
| 2023-07-24 00:00:00+08:00 | 5916.4 | 3812.0 | 2506.8 | 102.410 | 101.430 | 102.425 | 8682.0 | 17055.0 | 11015.0 | 23645.0 | ... | 3918.0 | 168910.0 | 15980.0 | 3793.0 | 12050.0 | 231050.0 | 5264.0 | 15505.0 | 4151.0 | 20015.0 |
| 2023-07-25 00:00:00+08:00 | 6019.6 | 3926.4 | 2586.0 | 102.010 | 101.285 | 101.850 | 8670.0 | 17160.0 | 11170.0 | 23685.0 | ... | 4017.0 | 170930.0 | 16100.0 | 3857.0 | 12140.0 | 234080.0 | 5342.0 | 15505.0 | 4210.0 | 20475.0 |
| 2023-07-26 00:00:00+08:00 | 6005.0 | 3915.2 | 2582.2 | 102.160 | 101.340 | 102.070 | 8637.0 | 17220.0 | 11170.0 | 23635.0 | ... | 4051.0 | 172990.0 | 15975.0 | 3851.0 | 12200.0 | 233730.0 | 5396.0 | 15545.0 | 4270.0 | 20665.0 |
| 2023-07-27 00:00:00+08:00 | 5964.0 | 3910.4 | 2581.8 | 102.255 | 101.375 | 102.175 | 8767.0 | 17265.0 | 11230.0 | 23405.0 | ... | 4080.0 | 170180.0 | 15925.0 | 3861.0 | 12175.0 | 235810.0 | 5504.0 | 15215.0 | 4296.0 | 20735.0 |
5 rows × 63 columns
计算收益率数据¶
用收益率去计算相关性更好
In [17]:
# 计算日收益率
returns_df = price_df.pct_change().dropna()
# 或者计算对数收益率(更适合相关性分析)
log_returns_df = np.log(price_df / price_df.shift(1)).dropna()
print(f"收益率数据形状: {log_returns_df.shape}")
log_returns_df.head()
收益率数据形状: (52, 63)
Out[17]:
| IC | IF | IH | TF | TS | T | AP | CF | CJ | CY | ... | hc | ni | pb | rb | ru | sn | sp | ss | wr | zn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| datetime | |||||||||||||||||||||
| 2023-07-24 00:00:00+08:00 | -0.001520 | -0.005755 | -0.004855 | 0.000391 | 0.000296 | 0.000684 | 0.010653 | -0.014263 | 0.007747 | -0.008633 | ... | -0.003821 | -0.009545 | 0.003448 | -0.007878 | -0.005380 | -0.013072 | 0.005715 | 0.010699 | 0.006041 | -0.009201 |
| 2023-07-25 00:00:00+08:00 | 0.017293 | 0.029569 | 0.031105 | -0.003914 | -0.001431 | -0.005630 | -0.001383 | 0.006138 | 0.013974 | 0.001690 | ... | 0.024954 | 0.011888 | 0.007481 | 0.016732 | 0.007441 | 0.013029 | 0.014709 | 0.000000 | 0.014113 | 0.022723 |
| 2023-07-26 00:00:00+08:00 | -0.002428 | -0.002857 | -0.001471 | 0.001469 | 0.000543 | 0.002158 | -0.003813 | 0.003490 | 0.000000 | -0.002113 | ... | 0.008428 | 0.011980 | -0.007794 | -0.001557 | 0.004930 | -0.001496 | 0.010058 | 0.002576 | 0.014151 | 0.009237 |
| 2023-07-27 00:00:00+08:00 | -0.006851 | -0.001227 | -0.000155 | 0.000929 | 0.000345 | 0.001028 | 0.014939 | 0.002610 | 0.005357 | -0.009779 | ... | 0.007133 | -0.016377 | -0.003135 | 0.002593 | -0.002051 | 0.008860 | 0.019817 | -0.021457 | 0.006071 | 0.003382 |
| 2023-07-28 00:00:00+08:00 | 0.014680 | 0.024952 | 0.029087 | -0.000881 | -0.000296 | -0.001126 | 0.003189 | -0.001449 | -0.004910 | -0.006215 | ... | 0.009028 | 0.001644 | 0.002195 | -0.002593 | 0.002461 | -0.009159 | 0.007241 | -0.001644 | 0.001396 | -0.004350 |
5 rows × 63 columns
计算相关性矩阵¶
In [18]:
# 计算相关性矩阵
correlation_matrix = log_returns_df.corr()
print("相关性矩阵:")
display(correlation_matrix)
相关性矩阵:
| IC | IF | IH | TF | TS | T | AP | CF | CJ | CY | ... | hc | ni | pb | rb | ru | sn | sp | ss | wr | zn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IC | 1.000000 | 0.900112 | 0.817290 | -0.434765 | -0.375407 | -0.441313 | -0.105634 | 0.020993 | 0.095044 | 0.055888 | ... | 0.208862 | 0.059346 | -0.079617 | 0.201302 | -0.014600 | -0.037750 | 0.025207 | 0.019643 | 0.056838 | 0.305934 |
| IF | 0.900112 | 1.000000 | 0.973761 | -0.496040 | -0.458745 | -0.509177 | -0.035506 | 0.045574 | 0.039507 | -0.018200 | ... | 0.356031 | 0.127196 | 0.048458 | 0.282554 | 0.055559 | 0.086709 | 0.054249 | -0.041404 | 0.150787 | 0.379079 |
| IH | 0.817290 | 0.973761 | 1.000000 | -0.500667 | -0.478269 | -0.525351 | 0.015439 | 0.038280 | 0.036651 | -0.076567 | ... | 0.385441 | 0.103870 | 0.097502 | 0.293777 | 0.101448 | 0.081224 | 0.048746 | -0.064183 | 0.208034 | 0.373614 |
| TF | -0.434765 | -0.496040 | -0.500667 | 1.000000 | 0.906003 | 0.940551 | -0.109437 | -0.035830 | -0.119563 | -0.027588 | ... | -0.368322 | -0.328374 | -0.372022 | -0.370631 | -0.280430 | -0.159303 | -0.150972 | -0.164608 | -0.292355 | -0.248825 |
| TS | -0.375407 | -0.458745 | -0.478269 | 0.906003 | 1.000000 | 0.877678 | -0.084679 | -0.032557 | -0.076401 | 0.060346 | ... | -0.254003 | -0.246779 | -0.332170 | -0.263492 | -0.272916 | -0.114578 | -0.033723 | -0.031046 | -0.329850 | -0.241608 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| sn | -0.037750 | 0.086709 | 0.081224 | -0.159303 | -0.114578 | -0.183005 | -0.027739 | 0.188439 | 0.189247 | 0.174132 | ... | 0.222000 | 0.315602 | 0.101986 | 0.284906 | 0.090914 | 1.000000 | 0.167632 | 0.099075 | 0.027773 | 0.240526 |
| sp | 0.025207 | 0.054249 | 0.048746 | -0.150972 | -0.033723 | -0.132709 | -0.209718 | 0.463764 | 0.154405 | 0.484613 | ... | 0.400443 | 0.317552 | 0.298791 | 0.317577 | 0.201519 | 0.167632 | 1.000000 | 0.282997 | -0.006593 | 0.308170 |
| ss | 0.019643 | -0.041404 | -0.064183 | -0.164608 | -0.031046 | -0.103074 | -0.196821 | 0.099363 | 0.009026 | 0.123477 | ... | 0.283719 | 0.633708 | 0.282426 | 0.308476 | 0.210042 | 0.099075 | 0.282997 | 1.000000 | 0.079512 | 0.051384 |
| wr | 0.056838 | 0.150787 | 0.208034 | -0.292355 | -0.329850 | -0.295035 | 0.285010 | -0.002662 | -0.021198 | -0.130672 | ... | 0.329068 | 0.094858 | 0.245267 | 0.355793 | 0.185100 | 0.027773 | -0.006593 | 0.079512 | 1.000000 | 0.077570 |
| zn | 0.305934 | 0.379079 | 0.373614 | -0.248825 | -0.241608 | -0.283258 | 0.122151 | 0.454792 | 0.190481 | 0.392038 | ... | 0.348932 | 0.207255 | 0.320698 | 0.382269 | 0.313013 | 0.240526 | 0.308170 | 0.051384 | 0.077570 | 1.000000 |
63 rows × 63 columns
可视化相关性矩阵¶
In [19]:
# 热力图
plt.figure(figsize=(16, 14))
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool)) # 只显示下三角
sns.heatmap(correlation_matrix,
mask=mask,
annot=True,
cmap='RdBu_r',
center=0,
square=True,
fmt='.2f',
cbar_kws={"shrink": .8})
plt.title('期货品种收益率相关性矩阵', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()

高相关性品种分析¶
In [20]:
def analyze_high_correlations(corr_matrix, threshold=0.7):
"""
分析高相关性品种对
"""
high_corr_pairs = []
# 获取上三角部分
upper_triangle = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))
# 找出高相关性对
for i in range(len(corr_matrix.columns)):
for j in range(i+1, len(corr_matrix.columns)):
corr_value = upper_triangle.iloc[i, j]
if abs(corr_value) >= threshold:
high_corr_pairs.append({
'品种1': corr_matrix.columns[i],
'品种2': corr_matrix.columns[j],
'相关性': corr_value
})
# 转换为DataFrame并排序
high_corr_df = pd.DataFrame(high_corr_pairs)
high_corr_df = high_corr_df.sort_values('相关性', key=abs, ascending=False)
return high_corr_df
# 分析高相关性对
high_corr_df = analyze_high_correlations(correlation_matrix, threshold=0.6)
print("高相关性品种对 (|相关性| ≥ 0.6):")
display(high_corr_df)
高相关性品种对 (|相关性| ≥ 0.6):
| 品种1 | 品种2 | 相关性 | |
|---|---|---|---|
| 43 | bc | cu | 0.986287 |
| 2 | IF | IH | 0.973761 |
| 14 | PF | TA | 0.944964 |
| 4 | TF | T | 0.940551 |
| 3 | TF | TS | 0.906003 |
| 36 | l | pp | 0.902415 |
| 0 | IC | IF | 0.900112 |
| 54 | hc | rb | 0.884197 |
| 5 | TS | T | 0.877678 |
| 34 | jm | j | 0.847089 |
| 18 | PF | pp | 0.832319 |
| 1 | IC | IH | 0.817290 |
| 37 | l | v | 0.815011 |
| 26 | TA | pp | 0.811684 |
| 47 | lu | fu | 0.803179 |
| 6 | CF | CY | 0.787321 |
| 45 | lu | sc | 0.782370 |
| 39 | pp | v | 0.767150 |
| 13 | OI | y | 0.764574 |
| 48 | nr | pb | 0.732133 |
| 17 | PF | l | 0.729180 |
| 44 | bc | zn | 0.728089 |
| 53 | cu | zn | 0.724091 |
| 25 | TA | l | 0.714055 |
| 12 | OI | p | 0.704676 |
| 21 | SF | SM | 0.702404 |
| 41 | p | y | 0.701509 |
| 30 | b | y | 0.701328 |
| 32 | eb | pp | 0.683669 |
| 19 | PF | v | 0.680713 |
| 29 | b | p | 0.680544 |
| 31 | cs | c | 0.677935 |
| 27 | TA | v | 0.673799 |
| 46 | lu | bu | 0.672589 |
| 50 | sc | fu | 0.660532 |
| 20 | PF | hc | 0.656151 |
| 10 | MA | pp | 0.653106 |
| 33 | eg | v | 0.651396 |
| 11 | OI | b | 0.643773 |
| 40 | pp | hc | 0.643045 |
| 49 | nr | ru | 0.640103 |
| 55 | ni | ss | 0.633708 |
| 15 | PF | eb | 0.632000 |
| 51 | ag | au | 0.628418 |
| 16 | PF | eg | 0.627564 |
| 24 | TA | eg | 0.623004 |
| 52 | al | rb | 0.614706 |
| 42 | v | hc | 0.614702 |
| 22 | SF | v | 0.614683 |
| 7 | FG | m | 0.612013 |
| 8 | MA | eg | 0.609776 |
| 23 | TA | eb | 0.609102 |
| 35 | jm | rb | 0.603470 |
| 38 | l | hc | 0.602935 |
| 9 | MA | l | 0.601136 |
| 28 | TA | hc | 0.600183 |
低相关性品种分析¶
In [21]:
def analyze_low_correlations(corr_matrix, low_threshold=0.2, very_low_threshold=0.1):
"""
分析低相关性品种对
"""
low_corr_pairs = []
very_low_corr_pairs = []
negative_corr_pairs = []
# 获取上三角部分
upper_triangle = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))
for i in range(len(corr_matrix.columns)):
for j in range(i+1, len(corr_matrix.columns)):
corr_value = upper_triangle.iloc[i, j]
# 负相关性
if corr_value < 0:
negative_corr_pairs.append({
'品种1': corr_matrix.columns[i],
'品种2': corr_matrix.columns[j],
'相关性': corr_value,
'类型': '负相关'
})
# 非常低的正相关性
elif 0 <= corr_value <= very_low_threshold:
very_low_corr_pairs.append({
'品种1': corr_matrix.columns[i],
'品种2': corr_matrix.columns[j],
'相关性': corr_value,
'类型': '极低相关'
})
# 低相关性
elif corr_value <= low_threshold:
low_corr_pairs.append({
'品种1': corr_matrix.columns[i],
'品种2': corr_matrix.columns[j],
'相关性': corr_value,
'类型': '低相关'
})
return low_corr_pairs, very_low_corr_pairs, negative_corr_pairs
# 分析低相关性对
low_corr, very_low_corr, negative_corr = analyze_low_correlations(correlation_matrix,
low_threshold=0.2,
very_low_threshold=0.1)
# 转换为DataFrame
low_corr_df = pd.DataFrame(low_corr).sort_values('相关性')
very_low_corr_df = pd.DataFrame(very_low_corr).sort_values('相关性')
negative_corr_df = pd.DataFrame(negative_corr).sort_values('相关性')
print("低相关性品种对 (0.1 < 相关性 ≤ 0.2):")
display(low_corr_df.head(10))
print("\n极低相关性品种对 (0 ≤ 相关性 ≤ 0.1):")
display(very_low_corr_df.head(10))
print("\n负相关性品种对 (相关性 < 0):")
display(negative_corr_df.head(10))
低相关性品种对 (0.1 < 相关性 ≤ 0.2):
| 品种1 | 品种2 | 相关性 | 类型 | |
|---|---|---|---|---|
| 165 | SM | rr | 0.100275 | 低相关 |
| 68 | CJ | rr | 0.100303 | 低相关 |
| 90 | FG | SR | 0.100811 | 低相关 |
| 19 | IF | fu | 0.101190 | 低相关 |
| 38 | IH | ru | 0.101448 | 低相关 |
| 271 | lc | nr | 0.101632 | 低相关 |
| 286 | lu | sp | 0.101785 | 低相关 |
| 27 | IH | j | 0.101821 | 低相关 |
| 311 | pb | sn | 0.101986 | 低相关 |
| 210 | c | jm | 0.102429 | 低相关 |
极低相关性品种对 (0 ≤ 相关性 ≤ 0.1):
| 品种1 | 品种2 | 相关性 | 类型 | |
|---|---|---|---|---|
| 197 | cs | l | 0.000166 | 极低相关 |
| 178 | SR | wr | 0.000822 | 极低相关 |
| 63 | TF | p | 0.001748 | 极低相关 |
| 164 | SA | lc | 0.002117 | 极低相关 |
| 61 | TF | cs | 0.002770 | 极低相关 |
| 208 | c | si | 0.003143 | 极低相关 |
| 89 | AP | cu | 0.003685 | 极低相关 |
| 146 | PK | sc | 0.004962 | 极低相关 |
| 132 | OI | rr | 0.006792 | 极低相关 |
| 215 | c | wr | 0.007020 | 极低相关 |
负相关性品种对 (相关性 < 0):
| 品种1 | 品种2 | 相关性 | 类型 | |
|---|---|---|---|---|
| 35 | IH | T | -0.525351 | 负相关 |
| 20 | IF | T | -0.509177 | 负相关 |
| 33 | IH | TF | -0.500667 | 负相关 |
| 18 | IF | TF | -0.496040 | 负相关 |
| 34 | IH | TS | -0.478269 | 负相关 |
| 19 | IF | TS | -0.458745 | 负相关 |
| 2 | IC | T | -0.441313 | 负相关 |
| 0 | IC | TF | -0.434765 | 负相关 |
| 123 | TS | nr | -0.420527 | 负相关 |
| 76 | TF | nr | -0.416780 | 负相关 |
各品种的平均相关性分析¶
In [22]:
def analyze_average_correlations(corr_matrix):
"""
分析每个品种与其他所有品种的平均相关性
"""
avg_correlations = []
for symbol in corr_matrix.columns:
# 计算该品种与其他所有品种的相关性(排除自身)
other_correlations = corr_matrix[symbol].drop(symbol)
avg_corr = other_correlations.mean()
min_corr = other_correlations.min()
max_corr = other_correlations.max()
# 统计低相关性品种数量
low_corr_count = len(other_correlations[other_correlations <= 0.2])
very_low_corr_count = len(other_correlations[other_correlations <= 0.1])
negative_corr_count = len(other_correlations[other_correlations < 0])
avg_correlations.append({
'品种': symbol,
'平均相关性': avg_corr,
'最低相关性': min_corr,
'最高相关性': max_corr,
'低相关品种数(≤0.2)': low_corr_count,
'极低相关品种数(≤0.1)': very_low_corr_count,
'负相关品种数': negative_corr_count,
'总品种数': len(other_correlations)
})
return pd.DataFrame(avg_correlations).sort_values('平均相关性')
# 分析各品种的平均相关性
avg_corr_df = analyze_average_correlations(correlation_matrix)
print("各品种平均相关性排序(从低到高):")
display(avg_corr_df.head(15))
print("\n最不相关的品种(平均相关性最低):")
lowest_avg = avg_corr_df.nsmallest(10, '平均相关性')
display(lowest_avg)
print("\n最具独立性的品种(低相关品种数最多):")
most_independent = avg_corr_df.nlargest(10, '低相关品种数(≤0.2)')
display(most_independent)
各品种平均相关性排序(从低到高):
| 品种 | 平均相关性 | 最低相关性 | 最高相关性 | 低相关品种数(≤0.2) | 极低相关品种数(≤0.1) | 负相关品种数 | 总品种数 | |
|---|---|---|---|---|---|---|---|---|
| 5 | T | -0.138049 | -0.525351 | 0.940551 | 59 | 57 | 52 | 62 |
| 3 | TF | -0.113340 | -0.500667 | 0.940551 | 58 | 57 | 47 | 62 |
| 4 | TS | -0.082898 | -0.478269 | 0.906003 | 58 | 55 | 50 | 62 |
| 16 | RS | -0.020818 | -0.282279 | 0.295791 | 58 | 48 | 35 | 62 |
| 6 | AP | -0.006899 | -0.245507 | 0.285010 | 56 | 51 | 37 | 62 |
| 49 | au | 0.040071 | -0.246951 | 0.628418 | 55 | 44 | 24 | 62 |
| 38 | rr | 0.063384 | -0.251991 | 0.333571 | 54 | 35 | 20 | 62 |
| 0 | IC | 0.066316 | -0.441313 | 0.900112 | 49 | 40 | 18 | 62 |
| 26 | cs | 0.073678 | -0.225967 | 0.677935 | 50 | 39 | 20 | 62 |
| 41 | lc | 0.079862 | -0.275854 | 0.316132 | 47 | 30 | 17 | 62 |
| 1 | IF | 0.092779 | -0.509177 | 0.973761 | 47 | 34 | 15 | 62 |
| 8 | CJ | 0.100011 | -0.119563 | 0.316869 | 54 | 32 | 8 | 62 |
| 2 | IH | 0.101261 | -0.525351 | 0.973761 | 47 | 30 | 13 | 62 |
| 61 | wr | 0.124441 | -0.329850 | 0.369581 | 41 | 25 | 10 | 62 |
| 34 | m | 0.128738 | -0.214571 | 0.612013 | 40 | 31 | 12 | 62 |
最不相关的品种(平均相关性最低):
| 品种 | 平均相关性 | 最低相关性 | 最高相关性 | 低相关品种数(≤0.2) | 极低相关品种数(≤0.1) | 负相关品种数 | 总品种数 | |
|---|---|---|---|---|---|---|---|---|
| 5 | T | -0.138049 | -0.525351 | 0.940551 | 59 | 57 | 52 | 62 |
| 3 | TF | -0.113340 | -0.500667 | 0.940551 | 58 | 57 | 47 | 62 |
| 4 | TS | -0.082898 | -0.478269 | 0.906003 | 58 | 55 | 50 | 62 |
| 16 | RS | -0.020818 | -0.282279 | 0.295791 | 58 | 48 | 35 | 62 |
| 6 | AP | -0.006899 | -0.245507 | 0.285010 | 56 | 51 | 37 | 62 |
| 49 | au | 0.040071 | -0.246951 | 0.628418 | 55 | 44 | 24 | 62 |
| 38 | rr | 0.063384 | -0.251991 | 0.333571 | 54 | 35 | 20 | 62 |
| 0 | IC | 0.066316 | -0.441313 | 0.900112 | 49 | 40 | 18 | 62 |
| 26 | cs | 0.073678 | -0.225967 | 0.677935 | 50 | 39 | 20 | 62 |
| 41 | lc | 0.079862 | -0.275854 | 0.316132 | 47 | 30 | 17 | 62 |
最具独立性的品种(低相关品种数最多):
| 品种 | 平均相关性 | 最低相关性 | 最高相关性 | 低相关品种数(≤0.2) | 极低相关品种数(≤0.1) | 负相关品种数 | 总品种数 | |
|---|---|---|---|---|---|---|---|---|
| 5 | T | -0.138049 | -0.525351 | 0.940551 | 59 | 57 | 52 | 62 |
| 3 | TF | -0.113340 | -0.500667 | 0.940551 | 58 | 57 | 47 | 62 |
| 4 | TS | -0.082898 | -0.478269 | 0.906003 | 58 | 55 | 50 | 62 |
| 16 | RS | -0.020818 | -0.282279 | 0.295791 | 58 | 48 | 35 | 62 |
| 6 | AP | -0.006899 | -0.245507 | 0.285010 | 56 | 51 | 37 | 62 |
| 49 | au | 0.040071 | -0.246951 | 0.628418 | 55 | 44 | 24 | 62 |
| 38 | rr | 0.063384 | -0.251991 | 0.333571 | 54 | 35 | 20 | 62 |
| 8 | CJ | 0.100011 | -0.119563 | 0.316869 | 54 | 32 | 8 | 62 |
| 26 | cs | 0.073678 | -0.225967 | 0.677935 | 50 | 39 | 20 | 62 |
| 0 | IC | 0.066316 | -0.441313 | 0.900112 | 49 | 40 | 18 | 62 |
可视化低相关性品种¶
In [23]:
# 绘制平均相关性分布
plt.figure(figsize=(14, 8))
# 平均相关性直方图
plt.subplot(2, 2, 1)
plt.hist(avg_corr_df['平均相关性'], bins=30, alpha=0.7, color='skyblue', edgecolor='black')
plt.axvline(x=avg_corr_df['平均相关性'].mean(), color='red', linestyle='--',
label=f'平均值: {avg_corr_df["平均相关性"].mean():.3f}')
plt.xlabel('平均相关性')
plt.ylabel('品种数量')
plt.title('品种平均相关性分布')
plt.legend()
plt.grid(True, alpha=0.3)
# 低相关性品种数量分布
plt.subplot(2, 2, 2)
plt.hist(avg_corr_df['低相关品种数(≤0.2)'], bins=20, alpha=0.7, color='lightgreen', edgecolor='black')
plt.xlabel('低相关性品种数量')
plt.ylabel('品种数量')
plt.title('各品种的低相关性伙伴数量分布')
plt.grid(True, alpha=0.3)
# 平均相关性最低的品种
plt.subplot(2, 2, 3)
lowest_10 = avg_corr_df.nsmallest(10, '平均相关性')
plt.barh(lowest_10['品种'], lowest_10['平均相关性'], color='lightcoral')
plt.xlabel('平均相关性')
plt.title('平均相关性最低的10个品种')
plt.grid(True, alpha=0.3)
# 低相关性伙伴最多的品种
plt.subplot(2, 2, 4)
most_independent_10 = avg_corr_df.nlargest(10, '低相关品种数(≤0.2)')
plt.barh(most_independent_10['品种'], most_independent_10['低相关品种数(≤0.2)'], color='lightblue')
plt.xlabel('低相关性品种数量')
plt.title('低相关性伙伴最多的10个品种')
plt.tight_layout()
plt.show()
寻找最佳分散组合¶
In [24]:
def find_diversification_pairs(corr_matrix, min_corr=0.1, max_corr=0.3):
"""
寻找适合分散投资的品种对
"""
diversification_pairs = []
upper_triangle = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))
for i in range(len(corr_matrix.columns)):
for j in range(i+1, len(corr_matrix.columns)):
corr_value = upper_triangle.iloc[i, j]
if min_corr <= abs(corr_value) <= max_corr:
diversification_pairs.append({
'品种1': corr_matrix.columns[i],
'品种2': corr_matrix.columns[j],
'相关性': corr_value,
'绝对相关性': abs(corr_value)
})
diversification_df = pd.DataFrame(diversification_pairs)
diversification_df = diversification_df.sort_values('绝对相关性')
return diversification_df
# 寻找适合分散投资的品种对(相关性在0.1-0.3之间)
diversification_df = find_diversification_pairs(correlation_matrix, min_corr=0.1, max_corr=0.3)
print("适合分散投资的品种对 (相关性在0.1-0.3之间):")
print(f"找到 {len(diversification_df)} 个品种对")
display(diversification_df.head(20))
适合分散投资的品种对 (相关性在0.1-0.3之间): 找到 830 个品种对
| 品种1 | 品种2 | 相关性 | 绝对相关性 | |
|---|---|---|---|---|
| 122 | TS | pp | -0.100008 | 0.100008 |
| 463 | SM | rr | 0.100275 | 0.100275 |
| 226 | CJ | rr | 0.100303 | 0.100303 |
| 268 | FG | SR | 0.100811 | 0.100811 |
| 45 | IF | fu | 0.101190 | 0.101190 |
| 564 | cs | bu | -0.101445 | 0.101445 |
| 78 | IH | ru | 0.101448 | 0.101448 |
| 723 | lc | nr | 0.101632 | 0.101632 |
| 756 | lu | sp | 0.101785 | 0.101785 |
| 59 | IH | j | 0.101821 | 0.101821 |
| 70 | IH | ag | -0.101854 | 0.101854 |
| 818 | pb | sn | 0.101986 | 0.101986 |
| 573 | c | jm | 0.102429 | 0.102429 |
| 310 | MA | wr | 0.102440 | 0.102440 |
| 482 | SR | pg | 0.102545 | 0.102545 |
| 665 | m | ss | -0.102709 | 0.102709 |
| 174 | T | ss | -0.103074 | 0.103074 |
| 488 | SR | cu | -0.103134 | 0.103134 |
| 678 | pg | wr | 0.103658 | 0.103658 |
| 76 | IH | ni | 0.103870 | 0.103870 |
按品种组分析低相关性¶
In [31]:
def analyze_group_diversification(corr_matrix, groups):
"""
分析不同品种组之间的相关性
"""
group_pairs = []
group_names = list(groups.keys())
for i in range(len(group_names)):
for j in range(i+1, len(group_names)):
group1 = group_names[i]
group2 = group_names[j]
# 获取两个组的品种
symbols1 = [s for s in groups[group1] if s in corr_matrix.columns]
symbols2 = [s for s in groups[group2] if s in corr_matrix.columns]
if symbols1 and symbols2:
# 计算组间平均相关性
group_corr_values = []
for sym1 in symbols1:
for sym2 in symbols2:
if sym1 in corr_matrix.index and sym2 in corr_matrix.columns:
group_corr_values.append(corr_matrix.loc[sym1, sym2])
if group_corr_values:
avg_corr = np.mean(group_corr_values)
min_corr = np.min(group_corr_values)
max_corr = np.max(group_corr_values)
group_pairs.append({
'组1': group1,
'组2': group2,
'平均相关性': avg_corr,
'最低相关性': min_corr,
'最高相关性': max_corr,
'组1品种数': len(symbols1),
'组2品种数': len(symbols2)
})
return pd.DataFrame(group_pairs).sort_values('平均相关性')
# 分析品种组间的相关性
group_corr_df = analyze_group_diversification(correlation_matrix, exchange_groups)
print("品种组间平均相关性(从低到高):")
display(group_corr_df.head(10))
print("\n最适合分散投资的品种组组合:")
lowest_group_pairs = group_corr_df.nsmallest(10, '平均相关性')
display(lowest_group_pairs)
品种组间平均相关性(从低到高):
| 组1 | 组2 | 平均相关性 | 最低相关性 | 最高相关性 | 组1品种数 | 组2品种数 | |
|---|---|---|---|---|---|---|---|
| 9 | 有色系 | 金融 | -0.041164 | -0.372022 | 0.379079 | 6 | 6 |
| 13 | 农产品 | 金融 | -0.004812 | -0.217545 | 0.285838 | 11 | 6 |
| 16 | 化工系 | 金融 | -0.004369 | -0.142182 | 0.143515 | 2 | 6 |
| 18 | 贵金属 | 金融 | 0.022240 | -0.184468 | 0.270645 | 2 | 6 |
| 20 | 金融 | 能源 | 0.053920 | -0.141977 | 0.198646 | 6 | 2 |
| 12 | 农产品 | 贵金属 | 0.074120 | -0.098973 | 0.372627 | 11 | 2 |
| 8 | 有色系 | 贵金属 | 0.111644 | -0.106374 | 0.392338 | 6 | 2 |
| 10 | 有色系 | 能源 | 0.133390 | -0.071306 | 0.355173 | 6 | 2 |
| 15 | 化工系 | 贵金属 | 0.139800 | 0.015813 | 0.310179 | 2 | 2 |
| 19 | 贵金属 | 能源 | 0.147739 | 0.014247 | 0.258913 | 2 | 2 |
最适合分散投资的品种组组合:
| 组1 | 组2 | 平均相关性 | 最低相关性 | 最高相关性 | 组1品种数 | 组2品种数 | |
|---|---|---|---|---|---|---|---|
| 9 | 有色系 | 金融 | -0.041164 | -0.372022 | 0.379079 | 6 | 6 |
| 13 | 农产品 | 金融 | -0.004812 | -0.217545 | 0.285838 | 11 | 6 |
| 16 | 化工系 | 金融 | -0.004369 | -0.142182 | 0.143515 | 2 | 6 |
| 18 | 贵金属 | 金融 | 0.022240 | -0.184468 | 0.270645 | 2 | 6 |
| 20 | 金融 | 能源 | 0.053920 | -0.141977 | 0.198646 | 6 | 2 |
| 12 | 农产品 | 贵金属 | 0.074120 | -0.098973 | 0.372627 | 11 | 2 |
| 8 | 有色系 | 贵金属 | 0.111644 | -0.106374 | 0.392338 | 6 | 2 |
| 10 | 有色系 | 能源 | 0.133390 | -0.071306 | 0.355173 | 6 | 2 |
| 15 | 化工系 | 贵金属 | 0.139800 | 0.015813 | 0.310179 | 2 | 2 |
| 19 | 贵金属 | 能源 | 0.147739 | 0.014247 | 0.258913 | 2 | 2 |
时间序列的低相关性稳定性分析¶
In [26]:
def analyze_correlation_stability(returns_df, symbol_pairs, window=60):
"""
分析低相关性品种对的相关性稳定性
"""
stability_results = []
for _, row in symbol_pairs.head(20).iterrows():
symbol1, symbol2 = row['品种1'], row['品种2']
if symbol1 in returns_df.columns and symbol2 in returns_df.columns:
# 计算滚动相关性
rolling_corr = returns_df[symbol1].rolling(window=window).corr(returns_df[symbol2])
# 计算稳定性指标
corr_std = rolling_corr.std() # 标准差越小越稳定
corr_range = rolling_corr.max() - rolling_corr.min() # 范围越小越稳定
stable_ratio = len(rolling_corr[(rolling_corr >= -0.3) & (rolling_corr <= 0.3)]) / len(rolling_corr)
stability_results.append({
'品种1': symbol1,
'品种2': symbol2,
'平均相关性': row['相关性'],
'相关性标准差': corr_std,
'相关性范围': corr_range,
'稳定比例': stable_ratio,
'稳定性评分': (1 - corr_std) * stable_ratio # 综合评分
})
return pd.DataFrame(stability_results).sort_values('稳定性评分', ascending=False)
# 分析低相关性品种对的稳定性
stability_df = analyze_correlation_stability(log_returns_df, diversification_df)
print("低相关性品种对的稳定性分析:")
display(stability_df.head(15))
低相关性品种对的稳定性分析:
| 品种1 | 品种2 | 平均相关性 | 相关性标准差 | 相关性范围 | 稳定比例 | 稳定性评分 | |
|---|---|---|---|---|---|---|---|
| 0 | TS | pp | -0.100008 | NaN | NaN | 0.0 | NaN |
| 1 | SM | rr | 0.100275 | NaN | NaN | 0.0 | NaN |
| 2 | CJ | rr | 0.100303 | NaN | NaN | 0.0 | NaN |
| 3 | FG | SR | 0.100811 | NaN | NaN | 0.0 | NaN |
| 4 | IF | fu | 0.101190 | NaN | NaN | 0.0 | NaN |
| 5 | cs | bu | -0.101445 | NaN | NaN | 0.0 | NaN |
| 6 | IH | ru | 0.101448 | NaN | NaN | 0.0 | NaN |
| 7 | lc | nr | 0.101632 | NaN | NaN | 0.0 | NaN |
| 8 | lu | sp | 0.101785 | NaN | NaN | 0.0 | NaN |
| 9 | IH | j | 0.101821 | NaN | NaN | 0.0 | NaN |
| 10 | IH | ag | -0.101854 | NaN | NaN | 0.0 | NaN |
| 11 | pb | sn | 0.101986 | NaN | NaN | 0.0 | NaN |
| 12 | c | jm | 0.102429 | NaN | NaN | 0.0 | NaN |
| 13 | MA | wr | 0.102440 | NaN | NaN | 0.0 | NaN |
| 14 | SR | pg | 0.102545 | NaN | NaN | 0.0 | NaN |
低相关组合建议¶
In [32]:
def generate_diversification_recommendations(analysis_results):
"""
生成分散组合建议
"""
print("=" * 60)
print("分散组合建议")
print("=" * 60)
# 最佳分散品种对
print("\n1. 最佳分散品种对(低且稳定的相关性):")
best_pairs = analysis_results['stability_df'].head(5)
for i, (_, row) in enumerate(best_pairs.iterrows(), 1):
print(f" {i}. {row['品种1']} - {row['品种2']}: "
f"相关性={row['平均相关性']:.3f}, 稳定性评分={row['稳定性评分']:.3f}")
# 最具独立性品种
print("\n2. 最具独立性品种(平均相关性最低):")
independent_symbols = analysis_results['avg_corr_df'].head(5)['品种'].tolist()
print(f" {', '.join(independent_symbols)}")
# 最佳分散品种组组合
print("\n3. 最佳分散品种组组合:")
best_groups = analysis_results['group_corr_df'].head(3)
for i, (_, row) in enumerate(best_groups.iterrows(), 1):
print(f" {i}. {row['组1']} + {row['组2']}: 平均相关性={row['平均相关性']:.3f}")
# 生成建议
analysis_results = {
'stability_df': stability_df,
'avg_corr_df': avg_corr_df,
'group_corr_df': group_corr_df
}
generate_diversification_recommendations(analysis_results)
============================================================ 分散组合建议 ============================================================ 1. 最佳分散品种对(低且稳定的相关性): 1. TS - pp: 相关性=-0.100, 稳定性评分=nan 2. SM - rr: 相关性=0.100, 稳定性评分=nan 3. CJ - rr: 相关性=0.100, 稳定性评分=nan 4. FG - SR: 相关性=0.101, 稳定性评分=nan 5. IF - fu: 相关性=0.101, 稳定性评分=nan 2. 最具独立性品种(平均相关性最低): T, TF, TS, RS, AP 3. 最佳分散品种组组合: 1. 有色系 + 金融: 平均相关性=-0.041 2. 农产品 + 金融: 平均相关性=-0.005 3. 化工系 + 金融: 平均相关性=-0.004
主要品种组分析¶
In [28]:
# 按交易所分组分析
exchange_groups = {
'黑色系': ['rb', 'hc', 'i', 'j', 'jm', 'ZC'],
'有色系': ['cu', 'al', 'zn', 'pb', 'ni', 'sn'],
'农产品': ['a', 'b', 'm', 'y', 'p', 'c', 'cs', 'SR', 'CF', 'RM', 'OI'],
'化工系': ['MA', 'TA', 'FU', 'BU', 'RU', 'L', 'PP', 'V', 'EG', 'EB', 'PG'],
'贵金属': ['au', 'ag'],
'金融': ['IF', 'IC', 'IH', 'T', 'TF', 'TS'],
'能源': ['sc', 'lu']
}
def analyze_exchange_correlations(corr_matrix, groups):
"""
分析各品种组内的平均相关性
"""
group_results = {}
for group_name, symbols in groups.items():
# 找出数据中存在的品种
existing_symbols = [s for s in symbols if s in corr_matrix.columns]
if len(existing_symbols) > 1:
# 提取该组的相关性子矩阵
group_corr = corr_matrix.loc[existing_symbols, existing_symbols]
# 计算平均相关性(排除对角线)
mask = np.ones_like(group_corr, dtype=bool)
np.fill_diagonal(mask, False)
avg_corr = group_corr.values[mask].mean()
group_results[group_name] = {
'品种数量': len(existing_symbols),
'平均相关性': avg_corr,
'品种列表': existing_symbols
}
return pd.DataFrame(group_results).T.sort_values('平均相关性', ascending=False)
# 分析各品种组
group_analysis = analyze_exchange_correlations(correlation_matrix, exchange_groups)
print("各品种组内平均相关性:")
display(group_analysis)
各品种组内平均相关性:
| 品种数量 | 平均相关性 | 品种列表 | |
|---|---|---|---|
| 能源 | 2 | 0.78237 | [sc, lu] |
| 贵金属 | 2 | 0.628418 | [au, ag] |
| 化工系 | 2 | 0.575381 | [MA, TA] |
| 农产品 | 11 | 0.342479 | [a, b, m, y, p, c, cs, SR, CF, RM, OI] |
| 有色系 | 6 | 0.299943 | [cu, al, zn, pb, ni, sn] |
| 金融 | 6 | 0.079711 | [IF, IC, IH, T, TF, TS] |
| 黑色系 | 6 | NaN | [rb, hc, i, j, jm, ZC] |
保存分析结果¶
In [30]:
# 保存相关性矩阵
correlation_matrix.to_csv('futures_correlation_matrix.csv', encoding='utf-8-sig')
# 保存高相关性对
high_corr_df.to_csv('high_correlation_pairs.csv', encoding='utf-8-sig', index=False)
print("分析结果已保存到CSV文件")
分析结果已保存到CSV文件
Related Articles


Comment
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果